
Introduction
Many people today view ChatGPT as a one-size-fits-all solution for their AI needs, akin to wearing the same pair of shoes for every occasion. However, just as you wouldn’t wear running shoes to a formal dinner or dress shoes on a hiking trip, it’s crucial to recognize that different large language models are designed for specific tasks and contexts within artificial intelligence.
While ChatGPT is undoubtedly a powerful and versatile tool in natural language processing, it’s not the only player in the field of LLMs. Recent benchmarks comparing foundation models like Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, and Llama-400b reveal significant variations in performance across different tasks. For instance, Claude 3.5 Sonnet excels in graduate-level reasoning (59.46%) and code evaluation (92.0%), while GPT-4o leads in math problem-solving (76.6%). These benchmarks underscore that each model has its strengths and specializations, shaped by their unique neural networks, training data, and training processes. 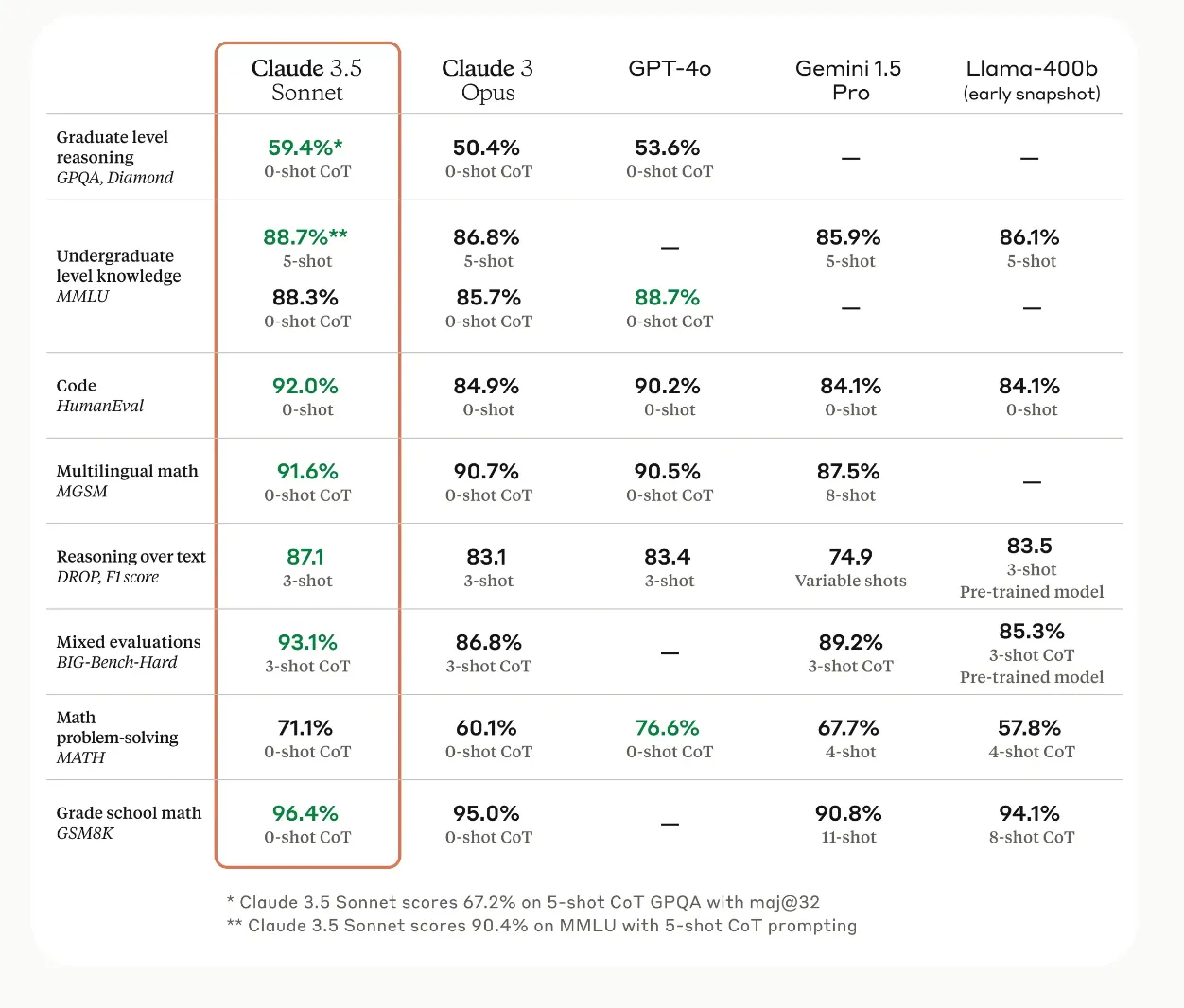
Source: Synthedia Substack
To truly harness the potential of AI, we need to develop a more nuanced approach to using these tools. This means taking the time to understand the strengths and limitations of different models and consciously choosing the right one for each task. For example:
- Software Development: If you’re working on a complex coding project, you might opt for Claude 3.5 Sonnet, which has a 92.0% performance on code evaluation tasks. Its strong grasp of human language and programming syntax makes it ideal for debugging, code optimization, and even explaining complex algorithms to junior developers.
- Financial Analysis: For intricate mathematical modeling and data interpretation in finance, GPT-4o might be the better choice due to its superior math problem-solving abilities (76.6%). It could assist in risk assessment, market trend analysis, and creating predictive models for investment strategies.
- Multilingual Customer Support: Claude 3.5 Sonnet’s high performance in multilingual math (91.6%) suggests strong language modeling capabilities in a global business setting. This could be leveraged to create a robust, multilingual customer support system that can understand and respond to queries in various languages, potentially reducing the need for human translators.
Just as a well-equipped shoe rack allows you to tackle any terrain or occasion, a diverse AI toolkit enables you to approach various challenges more efficiently and effectively. By moving beyond a one-model-fits-all mentality and leveraging benchmark data to inform our choices, we can unlock the full potential of what Large language models can do today.
It’s important to note that the field of large language models is rapidly evolving. Companies and researchers continuously work to maintain LLMs, often employing techniques like fine-tuning to adapt transformer models to specific tasks or domains. This ongoing development in AI means that these models’ capabilities and relative strengths may shift over time, further emphasizing the need for an adaptable, multi-model approach in leveraging AI for real-world applications.
Brief Overview of Large Language Models Capabilities in Customer Operations
Large Language Models, including proprietary and open-source options, are powerful generative AI tools transforming customer operations and sales processes.
These sophisticated deep learning models, available through platforms like Hugging Face and including models like Meta’s LLaMA, offer a broad range of capabilities:
Customer Engagement and Support
LLMs excel at generating content and identifying patterns in customer communications:
- A customer service team using GPT-4 or an open-source alternative from Hugging Face to draft personalized responses to customer inquiries, improving response times and satisfaction.
- An e-commerce platform employing BERT or Meta’s LLaMA to translate product descriptions and customer reviews into multiple languages, expanding global reach.
- A telecommunications company utilizing Claude or a fine-tuned open-source model to summarize customer feedback and identify trending issues for proactive problem-solving.
Sales and Marketing Enhancement
Through in-context learning, LLMs can boost sales and marketing efforts:
- A sales team leveraging ChatGPT or an open-source model from Hugging Face to craft tailored sales pitches based on prospect data and industry trends.
- A digital marketing agency using proprietary or open-source LLMs to generate and A/B test various ad copy variations, optimizing campaign performance.
- A CRM system enhanced with LLM capabilities, potentially using a fine-tuned version of Meta’s LLaMA, to provide sales reps with real-time insights and next-best-action recommendations during customer interactions.
Technical Support and Product Development
While not replacing specialized teams, LLMs can assist with technical aspects of customer operations:
- A technical support team using Codex or an open-source code generation model to generate troubleshooting scripts for common customer issues quickly.
- A product development team utilizing an LLM from Hugging Face to translate customer feedback into actionable feature requests for the engineering team.
- A UX research team employing GPT-4 or a fine-tuned open-source alternative to analyze open-ended survey responses and identify key themes in customer preferences.
Important for Sales and Customer Operations Leaders
- Versatility and Efficiency: Proprietary and open-source LLMs can adapt to various customer-facing tasks without reprogramming, processing customer information faster than human agents.
- Cost-Effectiveness: By leveraging these AI models, including open-source options, companies can potentially reduce costs while improving service quality.
- Continuous Improvement: As more customer interaction data is fed into these systems, including community-driven models on Hugging Face, they become increasingly adept at handling complex customer scenarios.
- Limitations and Oversight: While powerful, all LLMs may sometimes misinterpret customer intent or produce inappropriate responses. Human oversight remains crucial, especially for sensitive customer interactions.
- Accessibility: These models, particularly open-source ones like Meta’s LLaMA, can be fine-tuned for specific industries or customer bases, allowing even non-technical teams to harness their power effectively.
Remember, whether using proprietary or open-source LLMs, these tools are meant to augment human capabilities in customer operations and sales, not replace human judgment.

Source: https://arxiv.org/pdf/2404.00029v1
They’re most effective when used to enhance productivity and creativity in conjunction with human expertise, helping to uncover statistical relationships in customer data and generate innovative solutions across a broad range of customer-centric applications.
What Happens When You Ignore the Above?
Ignoring the emerging trends and opportunities in AI-powered customer service, particularly those leveraging large language models’ important capabilities to understand natural language, can have significant negative consequences for businesses. Intercom’s 2023 report on The State of AI in Customer Service highlights that 73% of support leaders believe that customers will expect AI-assisted customer service within the next five years. Companies that fail to meet these evolving customer expectations, which increasingly involve sophisticated text generation and language translation, risk falling behind their competitors and potentially losing market share.
The research indicates that early adopters of AI in customer service, utilizing advanced transformer models and deep learning techniques, already see tangible benefits. For instance, according to Intercom, 66% of support leaders have observed improvements in their CSAT scores, while 61% report better achievement of KPIs and SLAs thanks to AI and automation technologies. By ignoring these advancements, which often rely on bidirectional encoder representations and self-attention mechanisms to process input text, businesses may miss out on opportunities to enhance their customer experience, potentially leading to decreased customer satisfaction and loyalty.
Furthermore, efficiency gains from AI adoption are substantial, particularly in areas like programming languages and machine learning applications. As noted by BCG, AI-powered customer service solutions could increase productivity by 30% to 50% or more once implemented at scale. Companies that delay or resist AI adoption may find themselves at a significant competitive disadvantage regarding operational efficiency and cost-effectiveness, especially as language model performance improves.
The “AI readiness gap” identified in the Intercom report also suggests that organizations failing to prepare their teams for AI integration may face internal challenges. With only 44% of support practitioners excited about leveraging AI and automation (compared to 66% of leaders), companies risk creating a disconnect between leadership vision and frontline execution if they don’t address this gap.
Ignoring the potential of AI in customer service may also result in missed opportunities for career development and team growth. As the role of humans in customer service evolves, new positions, such as chatbot developers, conversation designers, and AI chatbot strategists, are emerging. These roles often require expertise in natural language processing and machine learning. Organizations that don’t embrace these changes may struggle to attract and retain top talent in an increasingly AI-driven industry.
Lastly, the financial implications of ignoring AI adoption in customer service can be substantial. With 60% of support leaders expecting to reduce support costs by adopting AI over the next five years, companies that lag in implementing large language models and other AI technologies may find themselves burdened with higher operational costs and diminished competitiveness in the long run.
Choosing the Right AI Model
The diversity of AI models ranges from general-purpose large language models (LLMs) like OpenAI’s GPT-4 and Google’s and Amazon’s models to specialized models tailored for niche applications. Hugging Face serves as a central hub for these models, allowing businesses to explore, compare, and implement various AI solutions. This platform enables organizations to leverage open-source and proprietary models, facilitating a more informed decision-making process.
I greatly support choosing the right model for the right task at the right time. All these areas require specific outputs like translating languages, writing software code, and language-related tasks like checking grammar and virtual assistants. Some areas combined are a good task for popular large language models like GPT, Gemini, and Claude. Other tasks require more specific models.
While very large models like GPT and BLOOM have demonstrated impressive capabilities in language generation and producing human-like text, companies should carefully consider their specific needs when choosing AI models. Different tasks often require specialized models for optimal performance. For instance, in the financial sector, models like FinBERT and FLANG have been tailored to handle domain-specific challenges. These models excel at sentiment analysis of financial news, named entity recognition of companies and financial instruments, and generating contextually relevant responses to market-related queries. They achieve this by training on vast amounts of financial data, allowing them to understand industry jargon and nuances that general models might miss.
Similarly, for tasks involving questions about Chinese financial markets, a model like XuanYuan 2.0 would likely outperform a general-purpose model due to its specialized training. Companies should, therefore, assess their particular use cases – whether it’s analyzing earnings reports, classifying financial headlines, or generating market summaries – and select models that have been specifically trained on relevant data and optimized for those tasks. This targeted approach ensures more accurate and reliable outputs than a one-size-fits-all solution.
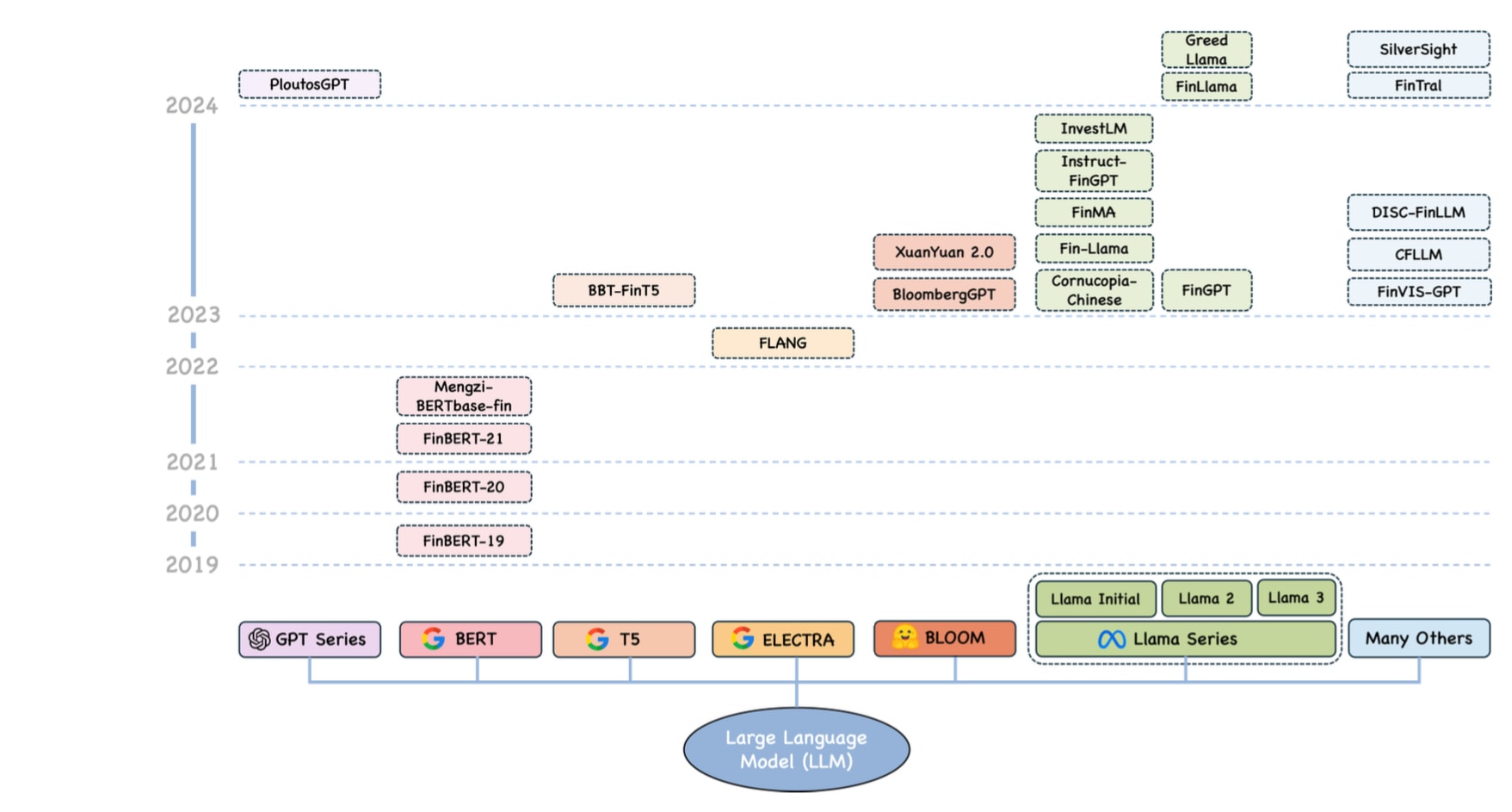
Overview of financially specialized large language models (LLMs) from 2019, categorized by their foundational model types and many others. Source: Arxiv
Selecting the Ideal AI Model for Your Business
Selecting an AI model for a specific challenge is a vast and complex topic. The task is multidimensional, making it difficult to provide a one-size-fits-all solution. However, I’ve prepared a step-by-step process to guide businesses closer to an optimal decision. While this approach may not guarantee a perfect choice, it will help organizations navigate the complexities of AI model selection and arrive at a well-informed decision.
Define Your Objectives and Categorize the Problem
Begin by clearly articulating what you want to achieve with AI:
- Identify Use Cases: Determine if you need to enhance customer service, generate content, identify patterns in data, or solve other specific business problems.
- Categorize the Problem: Is it a supervised learning task (with labeled data), unsupervised learning (finding patterns in unlabeled data), or reinforcement learning (optimizing through environment interaction)?
- Specify Output Type: Are you dealing with regression (predicting numbers) or classification (assigning data to categories)?
Example 1: E-commerce Product Recommendation System
An online retailer wants to implement a product recommendation system. This is a supervised learning task, where the model needs to identify patterns in customer purchase history and browsing behavior to suggest relevant products. The business could use a deep learning model, such as a neural collaborative filtering model, which can handle large-scale data and capture complex patterns in user-item interactions.
Assess Your Data Landscape
The nature and volume of your data significantly influence model choice:
- Data Volume: Large-scale models and deep learning models handle vast amounts of data well, while traditional machine learning models might perform better with smaller datasets.
- Data Type: Supervised learning models need labeled data, which can be costly. Unsupervised models work with unlabeled data but may struggle with noisy or irrelevant information.
- Data Dimensionality: Consider the number of features your model needs. More features can improve performance but also increase complexity and computing costs.
Evaluate Model Performance and Complexity
Balance performance needs with operational constraints:
- Accuracy Metrics: Look at precision, recall, and overall accuracy. High precision might be crucial for a content generation system to ensure quality output.
- Explainability: Some industries, like healthcare or finance, may require models with high explainability for regulatory compliance. Deep learning models often struggle in this area compared to simpler machine learning models.
- Complexity vs. Simplicity: More complex models can solve intricate patterns but are more challenging to maintain and understand.
Example 2: Financial Fraud Detection
A bank wants to improve its fraud detection system. They need a model that can quickly identify patterns indicative of fraudulent transactions. In this case, they might opt for a gradient-boosting machine learning algorithm like XGBoost. While not as complex as deep learning models, XGBoost is excellent at identifying patterns in structured data and balancing performance and explainability, which is crucial in the financial sector.
Consider Scalability and Future Needs
Think beyond immediate requirements:
- Adaptability: Choose models that can be fine-tuned or expanded (like LLama or BERT). A startup might begin with a pre-trained model, planning to fine-tune it as it collects more domain-specific data.
- Integration Capabilities: Ensure the model can integrate with your existing and planned tech stack. DataBricks or Snowflake already made this work, which could be an excellent consideration as the platform with the model embedded.
Assess Training and Operational Costs
Factor in both initial and ongoing expenses:
- Training Duration and Expenses: Some large-scale models deliver excellent accuracy but have high training costs. Evaluate if the improved performance justifies the expense. DataBricks was able to fine-tune models for several thousand dollars; they offer a great handbook on their website with step-by-step guidance.
- Inference Speed: Consider how quickly the model needs to process data and make predictions.
- Operational Costs: Factor in costs for running and maintaining the model over time.
Evaluate Sourcing Options
Decide how to acquire or develop your AI model:
- In-house Development: Building from scratch (expensive, requires extensive expertise).
- Open-source Models: Pre-trained models available in the market (cost-effective but may require significant adaptation). Hugging Face offers a plethora of them with rankings and benchmarks.
- Proprietary Models: Pre-trained models accessible through cloud services or platforms (faster implementation, advanced capabilities, but potentially higher costs).
Most organizations find options 2 and 3 more practical, especially when working with large-scale models or complex deep-learning architectures.
Example 3: Automated Content Generation for a Media Company
A media company wants to implement an AI system to generate short-form content for social media. They use a large-scale, pre-trained language model like GPT-3 or GPT-4o, Claude Sonnet 3.5. These models excel at generating human-like text and can be fine-tuned to the company’s existing content to match its style and tone. While using such a large pre-trained model can be expensive, it significantly reduces development time and provides high-quality output that requires minimal human editing.
Plan for Scaling
As you move from proof-of-concept to full production, consider:
- Data Residency Requirements: Understanding where data needs to be stored and processed is especially important for large-scale models handling sensitive information.
- Traffic Volume: Estimate the volume and impact of different solutions. Be aware of API rate limits in hosted solutions, particularly for models that generate content or identify patterns in real-time data streams.
- Skillset Requirements: Identify the skills needed to implement and maintain your chosen solution. Deep-learning models and large-scale models often require specialized expertise.
- Total Cost of Ownership: Estimate end-to-end costs, including development, maintenance, and operational expenses. Pre-trained models can reduce initial costs but may have higher ongoing expenses.
- Operational Capabilities: Evaluate whether to run AI deployments in-house or use managed services based on your internal capabilities and cost considerations.
By carefully considering these factors, you can select an AI model that meets your current needs and positions your business for future growth and innovation in the AI landscape. Whether you choose a traditional machine learning model, a deep learning architecture, or a large-scale pre-trained model, the key is to align your choice with your specific business objectives and operational realities.

Conclusion
Understanding that there is no “one size fits all” model and being aware of the differences between various AI models are vital to a company’s growth with artificial intelligence. LLMs can assist businesses in various fields, including support and sales, and are predicted to become an expected aspect of the business in the coming years. Learning about the strengths of various models and following a step-by-step process will aid in selecting the ideal model for a company’s current and future success.