
In this edition of my newsletter, I hope to bring you two compelling narratives that are shaping the future of business efficiency and data management.
First, we delve into an insightful case study from the Maspex Group, showcasing their groundbreaking project in business and IT collaboration.
Second, I’ll explore the critical realm of data cleaning, highlighting its importance in data analysis and offering practical Python-based techniques.
Maspex Group: Pioneering IT and Business Integration
I am delighted to present an insightful case study on a significant project that has reshaped the landscape of business and IT collaboration within the Maspex Group. As a leading entity in the food industry, known for brands like Tymbark, Kubuś, Łowicz, Żubrówka, and Lubella, Maspex Group has always been at the forefront of innovation and dynamic development. This project was an ambitious endeavor to set new standards in conducting transformation projects and designing efficient IT ecosystems.
Introduction:
Our journey began with a clear vision: to standardize the interaction between our IT department and business units, using data-driven analysis and automation. The objective was to enhance project reporting, streamline implementation processes, and preemptively identify unprofitable or risky projects. A key initiative was the creation of a unified WIKI platform, serving as a single source of truth and knowledge for our employees.
Addressing Core Challenges:
Harmonizing IT and Business Processes: We recognized the essential need for coherent and harmonious IT-business relations to effectively address market challenges. Our strategy involved reevaluating and refining cooperation standards, eliminating barriers to project execution, and introducing a unified system for internal customer expectations.
Navigating Diverse Business Requirements: The diverse and precise project specifications from various business units posed a significant challenge. It was crucial to define these requirements accurately to ensure efficient project execution, minimize errors, and manage project costs and timelines effectively.
Strategic Implementations:
- Defining Progress Indicators in Development Projects:
- We established a catalog of progress indicators, vital for monitoring and assessing project development.
- Cataloging IT Ecosystems:
- A comprehensive list of all IT ecosystems was created, an essential step for data management system integration and IT infrastructure development.
Achievements and Impact:
The results of this project have been transformative, with marked improvements in cooperation and understanding between IT and business units, leading to faster and more effective implementation of new IT solutions. Our approach to project management and IT ecosystem organization has set a new benchmark within the industry.
I invite you to delve deeper into this case study, which exemplifies our commitment to innovation and excellence at Maspex Group here: LINK
The Art and Science of Data Cleaning
In the realms of data analysis, statistics, and technology, the significance of data cleaning cannot be overstated. This process is the cornerstone of ensuring the accuracy and validity of data before it is used for analysis or decision-making. Our guide delves into the essence of data cleaning, its critical importance, and the methodologies to effectively execute it.
What is Data Cleaning?
Data cleaning, also known as data scrubbing, is the process of preparing raw data for analysis by sorting, evaluating, and correcting it. This process involves:
- Identifying and rectifying errors and missing values in data.
- Ensuring all information is accurate and consistent before uploading to databases.
- Organizing data to make it more interpretable and relevant for business applications.
The Importance of Data Cleaning
Data cleaning plays a pivotal role in data management for several reasons:
- Ensures Accuracy of Analysis: By removing irrelevant and duplicate data, it makes the raw data more reliable and complete, leading to more accurate analyses.
- Prepares Data for Transformation: Cleaning data is essential before converting it from one format to another, ensuring the accuracy of data sets for analysis.
- Removes Irrelevant Information: It helps in discarding unrelated data points, preventing inaccuracies and miscounts in the analysis.
- Makes Data Consistent: It is crucial for achieving data consistency, thereby reducing errors and ensuring uniformity across business operations.
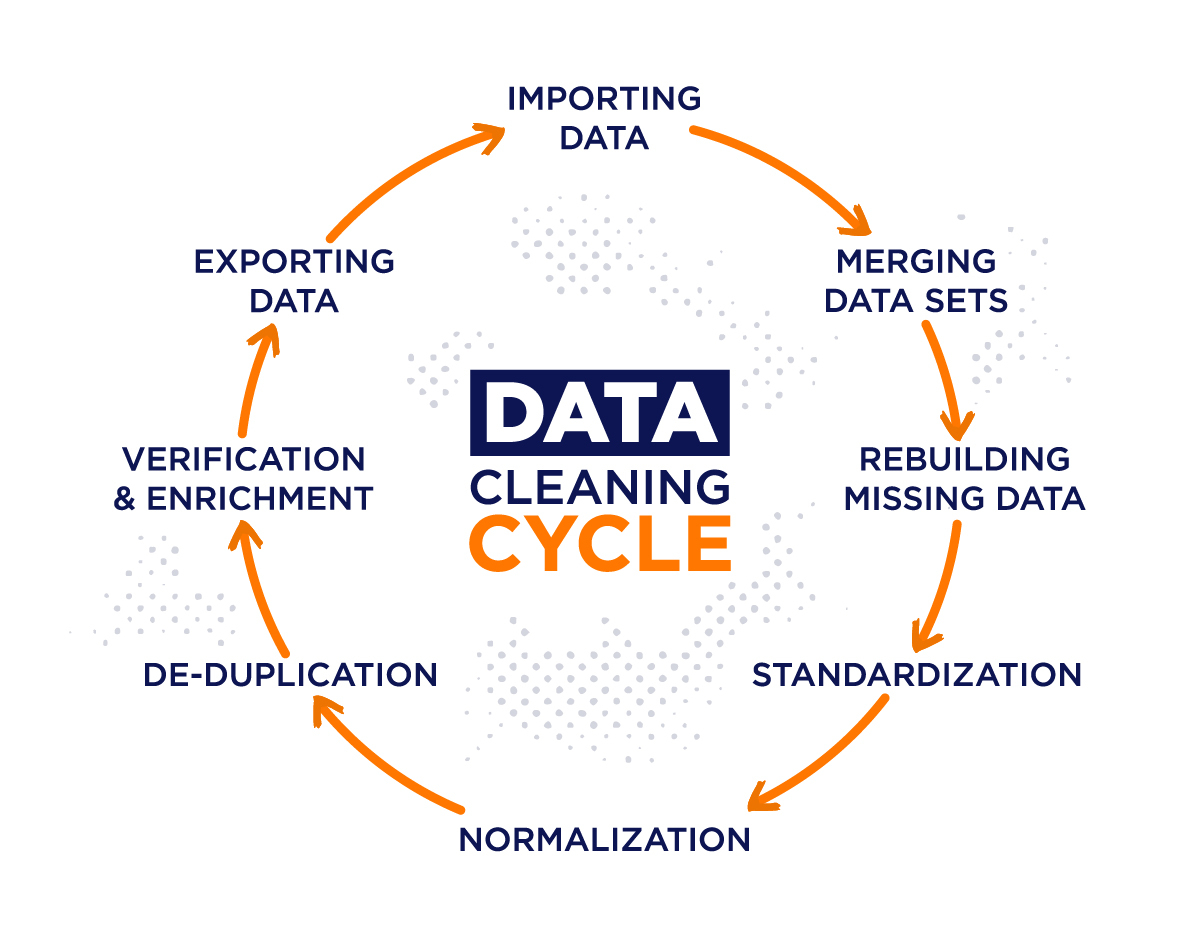
How to Clean Data: A Step-by-Step Approach
- Establish Data Cleaning Objectives: Assess your raw data for specific criteria and gather it in one location for cleaning.
- Create a Cleaning Template: Use a spreadsheet or table to organize criteria like unrelated data values, duplicates, errors, and incomplete data sets.
- Identify Duplicate Data: Look for repetitive information and decide whether any duplicates are necessary for your analysis.
- Eliminate Outliers: Remove unusual or unexpected values that may skew your data, unless they are essential for understanding your sample sets.
- Resolve Missing Data: Address omissions in your data, whether from errors in sampling or misrepresentation, using methods like reprogramming or estimation.
- Review Complete Data Set for Accuracy: After cleaning, evaluate your data for accuracy and completeness, ensuring it aligns with your objectives and criteria.
Tools for Data Cleaning
Several tools and resources can simplify the data cleaning process:
- Visualization and Modeling Software: Useful for summarizing data in charts, graphs, and models.
- Data Transformation Techniques: These include methods to aggregate, order, sort, filter, and transform data sets.
- Internal Data Management Tools: Such as media, email, and network logs, which assist in categorizing and interpreting data for various analyses.

Data Cleaning Techniques with Python
Python, with its powerful libraries like Pandas and NumPy, is a go-to choice for data cleaning. Here’s how to leverage Python for various data cleaning tasks:
- Handling Missing Values:
- Pandas provides methods like
isna(),fillna(), anddropna()to manage missing data.
- Pandas provides methods like
- Removing Duplicates:
- Use the
drop_duplicates()method to eliminate duplicate records.
- Use the
- Correcting Data Types:
- The
astype()method in Pandas is used to correct data types.
- The
- Standardizing Text Data:
- Clean text data by removing spaces and standardizing to a single case.
- Handling Outliers:
- Use NumPy and Pandas to detect and manage outliers, such as through z-score calculations.
- Cleaning Text Data:
- Regular expressions can be used to remove special characters, punctuation, and extra spaces.
- Dealing with Inconsistent Data:
- Pandas’
replace()function helps standardize inconsistent data.
- Pandas’
- Handling Categorical Data:
- Convert categorical data to numerical values using techniques like one-hot encoding or LabelEncoder.
- Data Imputation:
- Impute missing values using methods like mean, median, mode, or custom strategies.
- Data Validation:
- Validate data, checking for outliers or unrealistic values using tools like box plots.
Conclusion
Data cleaning is a fundamental step in the data lifecycle, crucial for maintaining the integrity and usefulness of data. The process, while sometimes complex, is essential for ensuring that the data sets used in your company’s operations are accurate, relevant, and reliable.
Sources:
https://medium.com/@LearnPytho…